Transformations create new objects and data sets from existing objects and data sets
buffering takes points, lines, or areas and creates areasevery location within the resulting area is either:in/on the original objectwithin the defined buffer width of the original object
Two versions
discrete object:Applicationsfor every object, result is a new polygon objectfield (objects cannot overlap):new objects may overlapevery location on the map has one of two values:inside buffer distance
outside buffer distanceevery location on the map has a value of distance to the nearest object
Determine whether a given point lies inside or outside a given polygon
Algorithma type of spatial join
assign a set of points to a set of polygons
e.g. count numbers of accidents in counties
e.g. whose property does this phone pole lie in?
draw a line from the point to infinityField casecount intersections with the polygon boundary
inside if the count is odd
outside if the count is even
Discrete object casepoint must lie in exactly one polygon
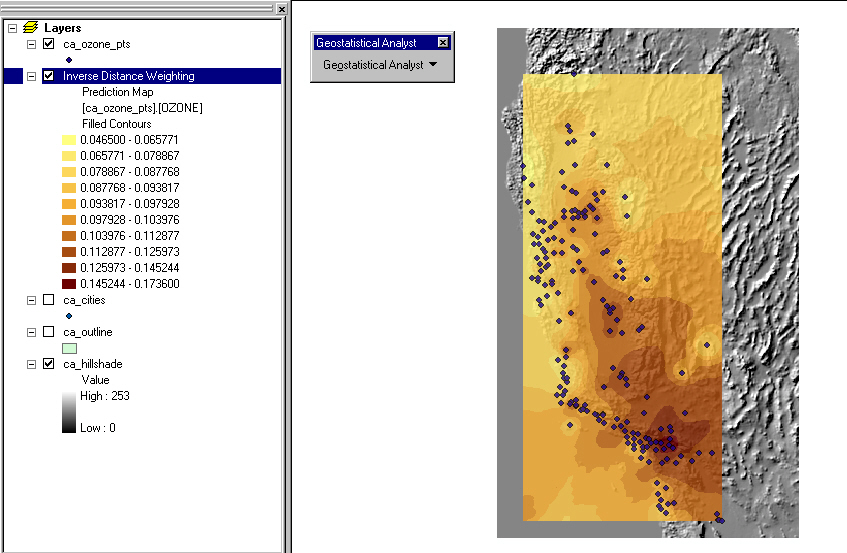
where are the California ozone monitoring stations?
and how are they distributed by California habitat?
point can lie in any number of polygons, including zero
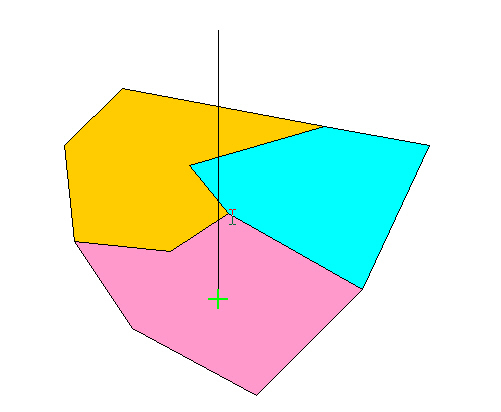
Create polygons by overlaying existing polygons
how many polygons are created when two polygons are overlaid?Discrete object case
find overlaps between two polygonsField casee.g. a property and an easementcreates a collection of polygons
overlay two complete coveragescreates a new coverage
e.g. find all areas that are owned by the Forest Service and classified as wetlandin vector or rasterin raster the values in each cell are combined, e.g. added
Areal interpolation
determining attributes for zones from other non-congruent zones
source zones
attributes are known
target zones
attributes are needed
overlay polygons, measure areas, use as weights
What is interpolation?
intelligent guessworkTwo methods commonly used in GISan interval/ratio variable conceived as a field
temperaturesampled at observation points
soil pH
population densityneeded:
values at other points
a complete surfacea contour map
a TIN
a raster of point values
inverse-distance weighting (IDW)Moving average/distance weighted average/inverse distance weightingKriging (geostatistics)
estimates are averages of the values at n known pointsExampleknown values z1,z2,...,znis the most widely used methodunknown value z = Sum over i (wizi) / Sum over i (wi)
where w is some function of distance, such as:
w = 1/dkan almost infinite variety of algorithms may be used, variations include:w = e-kd
the nature of the distance function
varying the number of points used
the direction from which they are selectedobjections to this method arise from the fact that the range of interpolated values is limited by the range of the data
no interpolated value will be outside the observed range of z valuessummary: IDW is popular, easy, but full of problemspeaks and pits will be missed if they are not sampled
outside the area sampled the surface must flatten to the average value
ozone concentrations at CA measurement stationsKrigingobjectives:
1. estimate a complete field, make a mapdata sets:
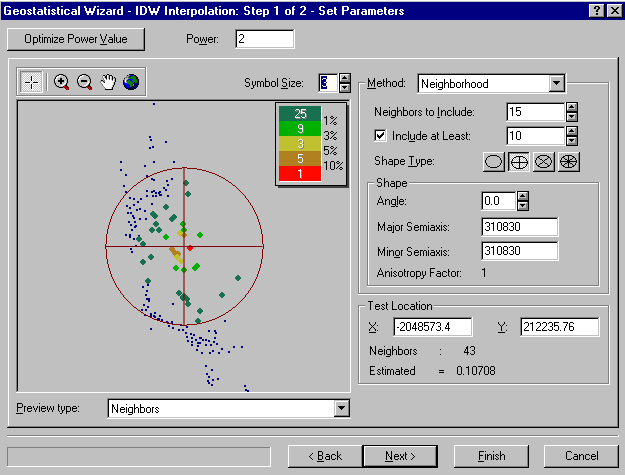
2. estimate ozone concentrations at other locationse.g. citiesmeasuring stations and concentrations (point shapefile)IDW wizard in Geostatistical Analyst
CA outline (polygon shapefile)
DEM (raster)
CA cities (point shapefile)opening screen defines data sourcethings to noticenext screen defines interpolation method
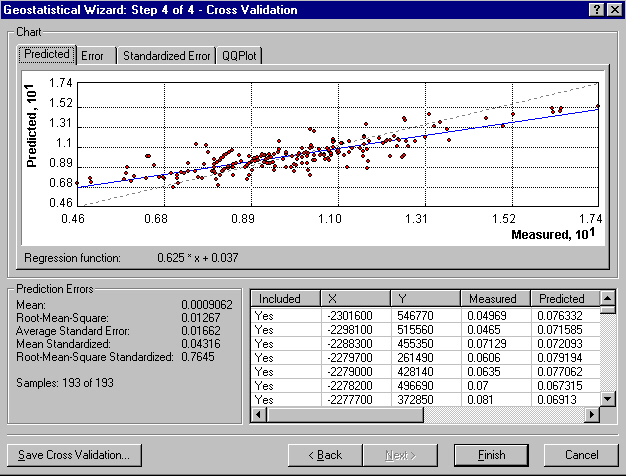
which power of distance? (2)next screen gives results of cross-validation
how many sectors? (4)
how many neighbors in each sector? (10-15)amount of detail where there is no datagenerally smooth surface
highs in LA, S central valley
developed by D.G. Krige as an optimal method of interpolation for use in the mining industryVariogramsthe rate at which the variance between points changes over space
expressed in the variogram
shows how the average difference between values changes with distance
analysis of the data
then application to interpolation
vertical axis is E(zi - zj)2Deriving the variogramthe average difference in elevation of any two points distance d apartmost variograms show behavior like the diagramd (horizontal axis) is distance between i and j
sill: the upper limit (asymptote)range: distance at which this limit is reached
nugget: intersection with the y axis
an irregularly spaced sample of pointsComputing the estimatesdivide the range of distance into a set of discrete intervals
e.g. 10 intervals between distance 0 and the maximum distance
for every pair of points, compute distance and the squared difference in z valuesassign each pair to one of the distance ranges
accumulate total variance in each range
compute the average variance in each distance range
plot this value at the midpoint distance of each range
fit one of a standard set of curve shapes to the points
"model" the variogram
variogram is used to estimate distance weights for interpolationweights are selected so that the estimates are:
unbiased (if used repeatedly, Kriging would give the correct result on average)problems with this method:minimum variance (variation between repeated estimates is minimum)
when the number of data points is large this technique is computationally very intensivethe estimation of the variogram is not simple, no one technique is best
results from this technique can never be absolute
example
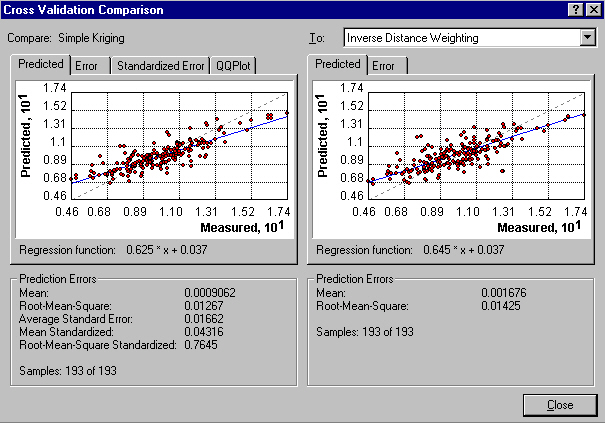
selection of methodsimple Krigingthings to noticeco-Kriging includes a correlated variableanalysis of the variogram
indicator Kriging is for binary datafitting a modelhow many neighbors?
directional effectssimilar patternless detail in remote areasrebounds to the mean at the edge
smoother
Suppose you had a map of discrete objects and wanted to calculate their density
density of populationMethodsdensity of cases of a disease
density of roads in an area
density would form a field
density estimation is one way of creating a field from a set of discrete objects
count the number of points in every cell of a rasterDensity estimation using kernelsmeasure the length of lines, e.g. roadsresult depends on cell sizeresult is very noisy, erratic
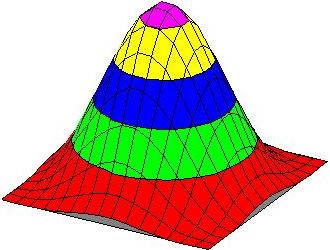
think of each point being replaced by a pile of sand of constant shapeDensity estimation and spatial interpolation applied to the same dataadd the piles to create a surface
example kernel
width of the kernel determines the smoothness of the surface
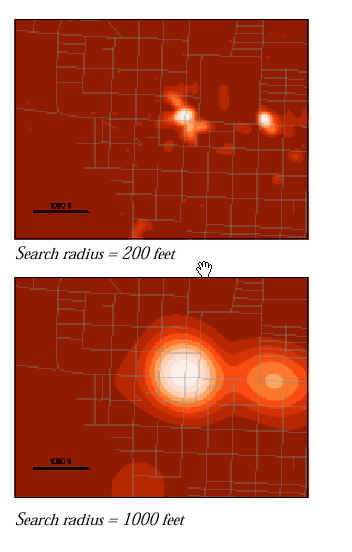
density of ozone measuring stationsusing Spatial Analyst
kernel is too small (radius of 16 km)what's the difference?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}